|
Let's begin with a history lesson. The origins of markup languages Berners-Lee defined HTML in SGML, the Standard Generalized Markup Language. SGML, like XML, is a metalanguage -- a language used for defining other languages. Each so-defined language is called an application of SGML. HTML is an application of SGML. SGML emerged from research done primarily at IBM on text document representation in the late '60s. IBM created GML ("General Markup Language"), a predecessor language to SGML, and in 1978 the American National Standards Institute (ANSI) created its first version of SGML. The first standard was released in 1983, with the draft standard released in 1985, and the first standard was published in 1986. Interestingly enough, the first SGML standard was published using an SGML system developed by Anders Berglund at CERN, the organization that, as we have seen, gave us HTML and the Web. SGML is widely used in large industries and governments such as in large aerospace, automotive, and telecommunications companies. SGML is used as a document standard at the United States Department of Defense and the Internal Revenue Service. (For readers outside of the US, the IRS are the tax guys.) Albert Einstein said everything should be made as simple as possible, and no simpler. The reason SGML isn't found in more places is that it's extremely sophisticated and complex. And HTML, which you can find everywhere, is very simple; for a lot of applications, it's too simple. HTML: All form and no substance Admittedly, artists and hackers have been able to work miracles with the relatively dull tool called HTML. But HTML has serious drawbacks that make it a poor fit for designing flexible, powerful, evolutionary information systems. Here a few of the major complaints:
SGML has none of these weaknesses, but in order to be general, it's hair-tearingly complex (at least in its complete form). The language used to format SGML (its "style language"), called DSSSL (Document Style Semantics and Specification Language), is extremely powerful but difficult to use. How do we get a language that's roughly as easy to use as HTML but has most of the power of SGML? SUBHEAD_BREAK: Origins of XML As the Web exploded in popularity and people all over the world began learning about HTML, they fairly quickly started running into the limitations outlined above. Heavy-metal SGML wonks, who had been working with SGML for years in relative obscurity, suddenly found that everyday people had some understanding of the concept of markup (that is, HTML). SGML experts began to consider the possibility of using SGML on the Web directly, instead of using just one application of it (again, HTML). At the same time, they knew that SGML, while powerful, was simply too complex for most people to use. In the summer of 1996, Jon Bosak (currently online information technology architect at Sun Microsystems) convinced the W3C to let him form a committee on using SGML on the Web. He created a high-powered team of muckety-mucks from the SGML world. By November of that year, these folks had created the beginnings of a simplified form of SGML that incorporated tried-and-true features of SGML but with reduced complexity. This was, and is, XML. In March 1997, Bosak released his landmark paper, "XML, Java and the Future of the Web" (see Resources). Now, two years later (a very long time in the life of the Web), Bosak's short paper is still a good, if dated, introduction to why using XML is such an excellent idea. SGML was created for general document structuring, and HTML was created as an application of SGML for Web documents. XML is a simplification of SGML for general Web use. An XML conceptual example
First, we'll take an example of a recipe, and display it as one possible HTML document. Then, we'll redo the example in XML and discuss what that buys us. Now, there are a number of advantages to representing this recipe in HTML, as follows:
There's one major problem with HTML as a data format, however. The meaning of the various pieces of data in the document is lost. It's really hard to take general HTML and figure out what the data in the HTML mean. The fact that there's an
Now, the idea of data in an HTML document meaning something may be a bit hard to grasp. Web pages are fine for the human reader, but if a program is going to process a document, it requires unambiguous definitions of what the tags mean. For instance, the Sure, you could write a program that grabs the headers out of the document, reads the table column headers, figures out the quantities and units of each ingredient, and so on. The problem is, everyone formats recipes differently. What if you're trying to get this information from, say, the Julia Childs Web site, and she keeps messing around with the formatting? If Julia changes the order of the columns or stops using tables, she'll break your program! (Though it has to be said: If Julia starts publishing recipes like this, she may want to think about changing careers.) Now, imagine that this recipe page came from data in a database and you'd like to be able to ship this data around. Maybe you'd like to add it to your huge recipe database at home, where you can search and use it however you like. Unfortunately, your input is HTML, so you'll need a program that can read this HTML, figure out what all the "Ingredients," "Instructions," "Units," and so forth are, and then import them to your database. That's a lot of work. Especially since all of that semantic information -- again, the meaning of the data -- existed in that original database but were obscured in the process of being transformed into HTML. Now, imagine you could invent your own custom language for describing recipes. Instead of describing how the recipe was to be displayed, you'd describe the information structure in the recipe: how each piece of information would relate to the other pieces.
XML example
Listing 3. A custom markup language for recipes It will come as little surprise to you, being the astute reader you are, that this recipe in its new format is actually an XML document. Maybe the fact that the file started with the odd header
gave it away; in fact, every XML file should begin with this header. We've simply invented markup tags that have a particular meaning; for example, "An
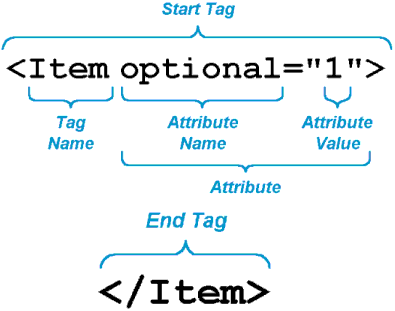
Notes on notation
Not every tag encloses text. In HTML, the
In addition to these notational differences from HTML, the structural rules of XML are more strict. Every XML document must be well-formed. What does that mean? Read on!
Ooh-la-la! Well-formed XML
looks (sort of) like math, but it isn't math because it doesn't follow the notational and structural rules for a mathematical expression (not on this planet, at least). In other words, the "expression" above isn't well-formed. Mathematical expressions must be well-formed before you can do anything useful with them, because expressions that aren't well-formed are meaningless. A well-formed XML document is simply one that follows all of the notational and structural rules for XML. Programs that intend to process XML should reject any input XML that doesn't follow the rules for being well-formed. The most important of these rules are as follows:
'Well-formed' means 'parsable'
For example, most browsers will display a document that (nonsensically) has two For another example, imagine that in Listing 3 the "cottage cheese" ingredient looked like this:
This XML document is certainly well-formed, but it doesn't make sense. It isn't structurally valid. It is nonsense for a
The problem is, we have a document that's well-formed, but it isn't very useful because the XML doesn't make sense. We need a way to specify what makes an XML document valid. For example, how can we specify that a The answer to this question lies in something called the document type definition, which we'll look at next. SUBHEAD_BREAK: Make up a markup While a well-formed document is well-formed because it follows rules defined by the XML spec, a valid document is valid because it matches its document type definition (DTD). The DTD is the grammar for a markup language, defined by the designer of the markup language. For my little XML recipe in Listing 3, for example, that designer would be me. The DTD specifies what elements may exist, what attributes the elements may have, what elements may or must be found inside other elements, and in what order.
Nonvalidating parsers read the XML and, if it's well-formed, give you back the document structure as a tree of objects. We'll discuss the document structure you get from a parser in the section below entitled "The Document Object Model." If the document is well-formed but the elements are nonsensical (as was the case with the two This is, in fact, how HTML browsers work. Generally, HTML parsers are nonvalidating. The various "HTML checking" parsers, which report sytax errors in HTML, are essentially validating HTML parsers (with additional functionality, like link checking). Validating parsers read XML, verify that it's well-formed (just as nonvalidating parsers do), and then go on to determine whether the document's element tags are legal, whether the attribute names make sense, whether every element nested inside another element belongs there, and so on. The DTD defines the document type. It accounts for the Extensible in XML. The DTD is how you actually define a new markup language -- what I often call a dialect of XML. DTDs currently are being written for an enormous number of different problem domains, and each DTD defines a new markup language. New markup languages now exist, or are being designed, to mark up the plays of Shakespeare; to define general data resources (RDF); to model information in the health care industry (HL7 SGML/XML); to typeset, display, and actively use mathematical equations (MathML); and to perform electronic data interchange (XML/EDI). There's even a proposal for a markup language for business data in the footwear industry (FDX). (No, I'm not joking.) Central to each of these new languages is a DTD that describes what tags the markup language has, what those tags' attributes may be, and how they may be combined. A DTD specifies very clearly what information may or may not be included in a markup language. For instance, the DTD for HTML does not allow for markup tags to select paper size for printing. Let's take a look at a DTD for the recipe XML in Listing 3. I'm going to call it JWSRML (JavaWorld Scary Recipe Markup Language). Apologies to anyone already using that acronym.
Listing 4. The DTD for JWSRML The document type definition in Listing 4 defines a language for a validating parser to accept -- meaning, the parser will produce errors if the rules listed in the DTD aren't followed. To get a general idea of how a DTD works, let's look at what a few of the lines in this file mean.
A DTD is associated with an XML document by way of a document type declaration, which appears at the top the XML file (after the
tells the parser to start looking for a There are other characters and notations in the DTD, but writing DTDs is a topic unto itself. If you're interested in learning more, check out the DTD-related links in Resources. You now know a lot about how XML is structured and controlled, but you haven't heard what it's good for. Why are people so excited about this technology? So, what good is made-up markup?
In fact, CSS (Cascading Style Sheets) and XSL (the Extensible Stylesheet Language) do precisely that: They're the style languages for XML. Let's take a quick look at these two technologies.
In Listing 3 above, you've seen what may be your first XML document. You've got a problem with that document, though: It's going to be pretty difficult to convince the browser manufacturers (not to mention the W3C) to add the The members of the appropriate committees at the W3C have addressed these concerns with two specifications: CSS and XSL. While both are declarative languages (meaning that there are no instructions in the first-do-this, then-do-that sense), they serve different functions. CSS exists as a current recommendation from the W3C, usable with HTML or XML, is simpler to use and less powerful than XSL, and is supported by most current-generation browsers (to varying degrees). XSL is used exclusively to format XML or SGML and is more complex and powerful than CSS. Great strides have been made with XSL in the past year. While XSL is still just a "working draft" (meaning its design isn't yet complete), you can experiment today with working implementations of the draft. Just this month (March 18, 1999), Microsoft released Internet Explorer 5.0, which includes support for part of the XSL specification. And Mozilla (the open source project based on the Netscape source code) can display XML using CSS. At the XTech '99 conference in San Jose, CA, in early March, Sun Microsystems "pre-announced" a request for proposals (for a grant) and a contest relating to the implementation of an XSL batch-processor and the addition of full XSL to Mozilla. (See Resources.) Again, the purpose of creating these new standards is to make most things very simple for most people, just like HTML has made hypertext and structured documents attainable to your grandma (or your nine-year-old). SUBHEAD_BREAK: Cascading Style Sheets: not just for HTML anymore You probably already know that HTML documents have a common tree-like structure wherein elements are nested inside other elements. Nonetheless, take a look at Listing 5 below.
Listing 5. <HTML> contains <BODY> contains <H1> contains text
As the caption says, the The whole idea of a style sheet is to use these structural relationships to indicate where changes in text style, spacing, and so on should occur. Then, a style sheet can be "applied" to a document, to change its overall look. For example, Listing 6 shows a tiny style sheet that sets the font size, color, and underlining for the <H1> heading in Listing 5.
Listing 6. A style sheet that sets the style for <H1> in Listing 5
If this style sheet were to appear at the top of the document, most HTML browsers these days would use the settings in the style sheet (or simply "style"), and change all
<SPAN STYLE="color: red; font-size: 16pt; text-decoration: underline"> A Theory About the Brontosaurus </SPAN> (If this example doesn't show up properly, you either have styles turned off in your browser or you're using an old browser that doesn't support styles.) A document can reference its style sheet with a hyperlink, and some browsers allow you to switch style sheets for the document you're viewing, effectively changing how the document looks on the fly.
These style sheets are called cascading style sheets, because styles (like fonts, colors, and so on) for one markup element "cascade" down, and apply to all of the element's contents. For example, if a paragraph tag (
The example we just looked at was for HTML, but what about XML? CSS can be used to style XML, too, and in precisely the same way. You simply specify the style for, say, an Most browsers these days (Netscape 4 and above, Internet Explorer 3 and above, Opera 3.5 and above) implement CSS pretty consistently for HTML. You'll be reading a lot in the next few months about CSS and XML availability in browsers. Also, keep in mind that CSS could be used to apply style to documents on the server and serve "straight HTML" without the CSS markup.
As powerful as CSS is, it has one major limitation: It can't "transform" the data it's styling. CSS can make an HTML or XML document look different, and even hide elements, but it can't reshuffle, cross-reference, or restructure them. For example, say you wanted to transform the XML recipe in Listing 3 to the HTML in Listing 1. Notice that you want the title to appear both in the browser's title bar (in an HTML To take an existing XML structure and produce a new structure of something else (in this case, HTML), you need XSL: the Extended Style Language. XSL: I like your style Fortunately, the W3C committees discussing style, HTML, and XML have included in their design the Extensible Style Language, or XSL. XSL is based on DSSSL (and DSSSL-O, the online version of DSSSL), and also uses some of the style elements of CSS. It's simpler than DSSSL, while retaining much of its power (much like the relationship between XML and SGML). XSL's notation, however, may be surprising: it's XML. The simplest way to say it is: XSL is an XML document that specifies how to transform another XML document. Say, what?
Why XSL is so useful XSL can even transform XML into a different dialect of XML! This may sound crazy, but it's actually a pretty cool idea. For example, multiple presentations of the same information could be produced by several different XSL files applied to the same XML input. Or, let's say two systems speak different "dialects" of XML but have similar information requirements. XSL could be used to translate the output of the first system into something compatible with the input of the second system. These last few reasons are of special interest to Java programmers, since XSL can be used to translate between different languages in a distributed network of subsystems, as well as to format documents. Understanding how to use XSL in simple applications, like transforming XML to HTML, will help a Java developer understand XSL in general. Let's look at an example of how to transform XML to HTML with an XSL style sheet.
Formatting XML as HTML: An example The example below refers again to the XML recipe example in Listing 3. We're going to look at an XSL file that transforms the XML in Listing 3 into the HTML in Listing 1.
Listing 7. XSL used as an XML language that transforms XML into something else (A printable version of this file is in example.xsl).
Looking at this code you'll notice, first of all, that the file starts with the While we won't go over all the templates in the XSL file (since this isn't an XSL tutorial), Listing 8 provides a quick look at the first template in the file, just to get the general idea.
Listing 8. The first template from the XSL style sheet in Listing 7
Notice the
The XSL processor sees a The resulting HTML is very similar to the HTML we saw in Listing 1. If you want to study the XML, XSL, and resulting HTML, and want to learn how to use XSL to format XML yourself, see the links on XSL in the Resources section of this article.
Additional XSL capabilities XSL's design also includes embedded scripting. Currently, IBM's LotusXSL package (written in Java) provides the functionality of almost all of the current draft specification of XSL, including the ability to call embedded ECMAScript (the European standard JavaScript) from XSL templates. Of course, as always, with power comes complexity. Learning to write XSL isn't a piece of cake. But the power's there if you want it.
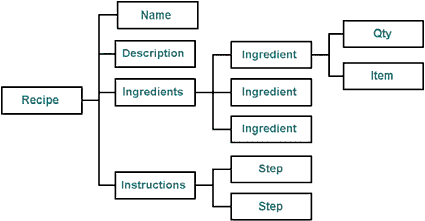
XML is more than just content management SUBHEAD_BREAK: Modeling information structure in XML So far, we've looked at XML as a way of representing data as human-readable documents, and we've spent some time discussing formatting. But XML's real power is in its ability to represent information structure -- how various pieces of information relate to one another -- in much the same way a database might. Structured documents of the type we've been looking at have the property that all of their elements nest inside one another, as in Listing 5 above. Instead of looking at a document as a file, though, consider what happens if we look at the structure of the tags as a tree:
The figure above shows the recipe as a tree of document tags. The child nodes of a document nest within the parent node. What if there were a way to automagically convert an XML document into a tree of objects in a programming language -- like, oh, say, Java maybe? And what if these objects all had properties that could be set and retrieved -- such as the list of each element's children, the text each object contained, and so on. Wouldn't that be interesting? The Document Object Model (DOM) Level 1 Recommendation (see Resources), created by a W3C committee, describes a set of language-neutral interfaces capable of representing any well-formed XML or HTML document. With the DOM, HTML and XML documents can be manipulated as objects, instead of just as streams of text. In fact, from the DOM point of view, the document is the object tree, and the XML, HTML, or what have you is simply a persistent representation of that tree. The availability of the DOM makes it much simpler to read and write structured document files, since standard HTML and XML parsers are written to produce DOM trees. If these objects have GUI representations, it's easy to see how to create an application that reads structured document files (XML or HTML), lets the user edit the structure visually, and then save it in its original format. Programs that interface with existing Web sites become much easier to write, because once the document is parsed, you're working with objects native to your programming language.
One of the earliest popular uses for the Document Object Model is Dynamic HTML, where client-side scripts manipulate and display (and redisplay) an HTML document in response to user actions. Dynamic HTML manipulates the client-side document in terms of the scripting language's binding to the DOM structure of the document being displayed. For instance, a But aside from all this browers-document-Web technology, the DOM provides a common way of accessing general data structures from structured documents. Any language that has a binding (that is, a specific set of interfaces that implement the DOM in that language) can use XML as an interface for storing, retrieving, and processing generic hierarchical (and even nonhierarchical) object structures.
How DOM and XML work together Let's think a moment about how DOM with XML would be useful in programming a database system. First, represent your database schema as a set of DOM objects. Want a document that describes that schema? No problem: write it out as XML. Use XSL to format the XML as HTML and you've got a complete, browseable schema reference that's always up to date. Want to automatically construct SQL for updating your relational database from a record set coming into your system? Just traverse your database's (DOM) schema tree, matching up the names of the columns from the record set with those of the schema, and build an SQL UPDATE statement as you go. What's that you say? The schema has changed, and the record set you've received doesn't match up with the new schema? You can write code to handle that, or present the user with error messages that state exactly what's wrong. You even might be able to use XSL to refactor the DOM tree of your record set into something matching the new schema. Finally, it's time to start programming in Java! In the next section, we're going to examine the Java bindings of the DOM and see how to use the DOM in a Java program. SUBHEAD_BREAK: XML and Java Up to this point I've been laying out general information about XML, without a lot of reference to Java. Now that you understand XML, it's time to look at how to process XML in Java. Java's a great language for XML, as you'll see. It provides a portable data format that nicely complements Java's portable code.
SAX appeal
To process an XML document, the programmer creates a class that implements
The methods of the
Listing 9. interface org.xml.sax.DocumentHandler
Package For example, say we want a class that counts the elements in an XML document. We could write a class as follows:
Listing 10. A class that counts the elements in an XML document
To create a Java program that counts elements in an XML file, you'd simply create a SAX parser (how you do that depends on your particular parser package), then create an instance of your
Experimenting with SAX
The package includes two document handlers: the You'll need the JAR file called "XMLApr99.jar," and you'll need to download the JAR file for IBM's excellent "XML for Java" package (version 2). Place both JAR files in your CLASSPATH, and type Part 1: Document Type Definitions and Valid XML As you learned a few weeks ago, a DTD is the grammar of an XML page. It is an acronym that stands for Document Type Definition. It contains the elements, attributes, entities, and notations used in the XML document.
Valid XML For example, while we haven't gone over the structure of a DTD yet, here is part of a simple one. It states that there is a root element called "family" that has two possible elements within it: "parent" and "child": <!DOCTYPE family [ If you were to write an XML document based upon that DTD, you could write: <?xml version="1.0" standalone="yes"?> This would be a valid XML document. But if I added extra text outside of the <parent> or <child> tags, the document would be invalid until I changed the DTD: ...
Part 2: Elements, Entities, Attributes, and Notations
Elements, entities, attributes and notations are the building blocks of a DTD.
Once you understand what each of these are, you can easily write your own
DTD and be on your way to writing XML applications.
Elements
Entities The file you use to write your XML declaration, document type declaration, and root element is called the document entity. In my example on the previous page, these would be:
Entities can be external to your XML document, like a well-formed stylesheet or XSL document, or internal and be something you define. The most common internal entity is a general entity. This is used as an abbreviation for commonly used text, or text that is difficult to type. Such as if you wanted to include the same copyright information on the bottom of each page, you could define that text as a "footer" entity and then insert &footer where you wanted it placed. To define an internal general entity, you use the <!ENTITY> tag in your DTD: <!ENTITY name "text to be replaced"> For example: writing out my name and title, "Jennifer Kyrnin, About HTML/XML Guide" is a bit long, but I can create an entity to add that into my XML documents with just four characters: <!ENTITY jkk "Jennifer Kyrnin, About HTML/XML Guide"> and every time I type &jkk; in an XML document with that DTD, it will expand to read "Jennifer Kyrnin, About HTML/XML Guide". To define an external entity, you create a very similar tag in your DTD, but you include the word "SYSTEM" so that the parser knows that this is an external entity. You also include the URI or location of the entity: <!ENTITY name system "URI">
Attributes When you create elements with attributes, you need to declare the possible attributes in your DTD. To do this, you use the <!ATTLIST> tag: <!ATTLIST element_name attribute_name type default_value>For example, my <parent> element might have the attribute of "role" with two options "father" or "mother". This would be defined as: <!ATTLIST parent role (father | mother) #required>In this example, I've assigned the element <parent> with the required attribute of "role". The attribute can be either "father" or "mother". There are ten types that can be assigned to attributes:
Notations The format for a notation is: <!NOTATION name system "external_ID"> The name identifies the format used in the document, and the external_id identifies the notation - usually with MIME-types. For example, to include a GIF image in your XML document: <!NOTATION GIF system "image/gif"> You can also use a "public" identifier, instead of "system". To do this you need to include both a public ID and a URI. Using the GIF example: <!NOTATION GIF public On the final page of this article, you will see what a simple DTD would look like within an XML document. Part 3: A Sample DTDDTDs are not difficult to write, but it is often easier to write an XML document first, and then define the DTD based upon what you wrote. For this example, I wrote an XML document based on a portion of a family tree. Once the document was finished, I wrote my DTD to match.
The XML Document <?xml version="1.0" standalone="yes"?> <family> <title>My Family</title> <parent role="mother">Judy</parent> <parent role="father">Layard</parent> <child role="daughter">Jennifer</child> <image source="JENN" /> <child role="son">Brendan</child> &footer; </family>
The DTD <!DOCTYPE family [ <!ELEMENT title (#PCDATA)> <!ELEMENT parent (#PCDATA)> <!ATTLIST parent role (mother | father) #required> <!ELEMENT child (#PCDATA)> <!ATTLIST child role (daughter | son) #required> <!NOTATION gif system "image/gif"> <!ENTITY JENN system "http://images.about.com/sites/guidepics/html.gif" NDATA gif> <!ELEMENT image empty> <!ATTLIST image source entity #required> <!ENTITY footer "Brought to you by Jennifer Kyrnin"> ]> XML Data IslandsThere is an increasing need to be able to embed "islands" of data inside HTML pages. In Microsoft® Internet Explorer 5.0 and later, these data islands can be written in XML. The following topics describe the syntax used for embedding these data islands within a page, and detail the object model exposed by the browser to enable them to be used. This method of embedding XML in HTML follows the note published by the Worldwide Web Consortium (W3C) as the "XML in HTML Meeting Report." The W3C expects to evolve the HTML specification to include the capability of embedding XML in HTML documents. Embedding an XML Data Island into an HTML PageAn XML data island can be embedded using one of the following methods.
Using the XML Element Within the HTML DocumentThis syntax is valid for Internet Explorer 5.0. There are two syntactically correct ways of using the XML element within the HTML document.
The XML element is present in the HTML Document Object Model. It is in the DHTML all collection and is seen by the browser as just a regular node. The XML data within the XML element can then be accessed by calling the DHTML XMLDocument property on the XML element. The XMLDocument property returns the root node of the XML within the XML element or the root node of the XML referenced by the value of the SRC attribute. From this root, the XML data island can be navigated using the XML Document Object Model (DOM). The following function returns the data from the data island with the ID of "XMLID". function returnXMLData(){
return document.all("XMLID").XMLDocument.nodeValue;
}
The XML element can also be referenced by ID alone. For example, the following function has the identical functionality as the preceding example. function returnXMLData(){
return XMLID.documentElement.text;
}
Because the XMLDocument property was not used, the documentElement property must be called to retrieve the root element of the XML. Overloading the HTML SCRIPT ElementThis syntax has been deprecated and is intended only for down-level cases. There are three syntactically correct ways of overloading the DHTML SCRIPT element.
The following HTML fragment illustrates how to embed data by overloading the SCRIPT element. <SCRIPT ID="XMLID" LANGUAGE="XML">
<XMLDATA>
<DATA>TEXT</DATA>
</XMLDATA>
</SCRIPT>
The SCRIPT element is present in the HTML page's object model. (It is in the DHTML all collection and is seen by the browser as a regular script node.) The XML data within the SCRIPT elements can be accessed by calling the XMLDocument property on the SCRIPT object. The following script accesses the XML data island in the preceding HTML fragment and returns the name of the root node of the XML data island. function returnIslandRootName(){
var islandRoot = document.all.("SCRIPT").XMLDocument;
return islandRoot.nodeName;
}
Note A tag that uses the name "XML" cannot be nested within an XML data island. |