
| Omrežja / Pajek |
| Program za analizo obsežnih omre`ij |
Uporabe v rodoslovju
Andrej Mrvar
Fakulteta za družbene vede
Univerza v Ljubljani
|
|
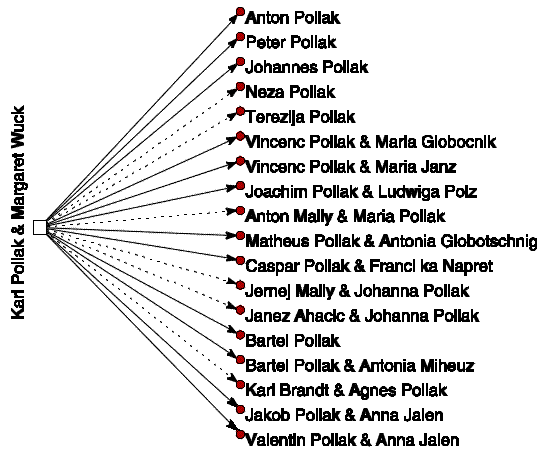
Vladimir Batagelj
FMF, Oddelek za matematiko
Univerza v Ljubljani
|
31. december 1997
Uvod
Pri svojem delu se večkrat srečamo z obsežnimi omrežji,
kjer gre število točk/povezav v tisoče.
Do teh omrežij lahko pogosto pridemo avtomatično iz drugih virov.
Naštejmo nekaj primerov:
rodovniki,
diagrami poteka programskih sistemov,
organske molekule, računalniška omrežja, transportna omrežja,
vodovodna in električna omrežja,
referenčna omrežja,
družboslovna omrežja, itd.
Obvladovanje tako velikih omrežij predstavlja tako časovno, kot
tudi prostorsko zahteven problem. Trenutno še ne obstaja veliko programov,
ki bi omogočali delo z njimi, zato sva se novembra 1996
odločila, da začneva z razvojem programskega paketa
za analizo velikih omrežij Pajek. Program je prosto
dostopen na naslovu:
http://vlado.fmf.uni-lj.si/pub/networks/pajek/
Rodovniki
Za izmenjavo rodoslovnih podatkov se uporablja oblika zapisa GEDCOM.
To obliko prepozna tudi program Pajek in jo predela v graf.
Pravzaprav lahko rodoslovne podatke predelamo v dve vrsti grafov --
rodovnikov:
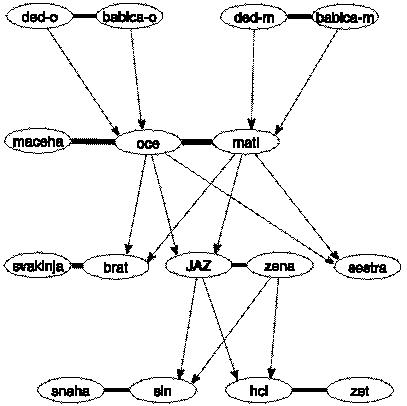
V navadni obliki je vsaka oseba
predstavljena s točko grafa, poroke so označene z neusmerjeno povezavo
med točkama, usmerjene povezave pa vodijo od staršev do otrok.
Glej primer na sliki 1.
Slika 1. Predstavitev rodovnika v navadni obliki.
EPS
|
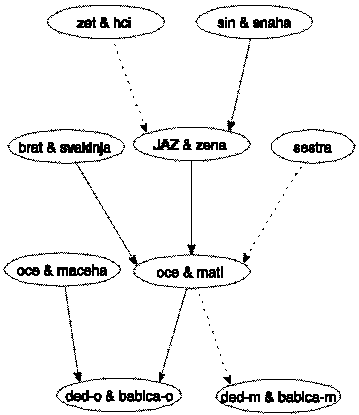
V obliki p-graph pa so točke grafa lahko posamezniki ali pari.
Več o tej obliki najdemo na predstavitveni strani dr. D. R. Whitea z
Univerze v Kaliforniji (Irvine):
http://eclectic.ss.uci.edu/~drwhite/pgraph/p-graphs.html
V primeru, da neka oseba še ni poročena,
je ta oseba v grafu predstavljena s svojo točko; če pa
je poročena, je v grafu predstavljena skupaj s svojim zakoncem
s skupno točko. V tej obliki imamo torej samo usmerjene povezave, ki
vodijo od otrok do staršev. Ker so točke lahko tudi pari,
moramo posebej označiti ali se povezava nanaša na moškega ali na
žensko. Povezave, ki se nanašajo na moške (kažejo na moževe starše)
so označene z neprekinjeno črto, povezave, ki se nanašajo na ženske
(kažejo na ženine starše) pa s prekinjeno (pikčasto) črto.
V primeru, da je neka oseba večkrat poročena, se ta oseba
pojavi v toliko točkah, kolikor je porok.
Glej primer na sliki 2.
Slika 2. Predstavitev rodovnika v obliki p-graph.
EPS
|
Analiza rodovnikov s Pajkom
V nadaljevanju so opisani osnovni koraki, ki jih moramo opraviti pri
uporabi programa Pajek, da dobimo željene rezultate.
Branje datoteke GEDCOM
Datoteko z rodoslovnimi podatki (v obliki GEDCOM)
preberemo z ukazom File/ Network/ Read
(poševne črte pomenijo zaporedne izbire)
ali pritisnemo ikono za branje, ki se nahaja v glavnem oknu desno
od besede Network (če se je dotaknemo z miško, se izpiše
Read Network).
Datoteka se prebere v obliki p-graph. Če želimo datoteko prebrati v
navadni obliki, moramo pred branjem spremeniti nastavitev s klikom na
Options/ ReadWrite/ GEDCOM - Pgraph.
Kako obrnemo smeri puščic
Kot smo opisali v prejšnjem podpoglavju, kažejo v obliki p-graph
puščice od otrok proti staršem. Za razumevanje je morda bolje
obrniti smeri puščic, kar naredimo z ukazom:
Net/ Transform/ Transpose. V nadaljevanju je v vseh primerih,
kjer je rodovnik prebran v obliki p-graph, uporabljena oblika z obrnjenimi
puščicami (puščice kažejo od staršev proti otrokom).
Risanje rodovnika
Za risanje rodovnikov se je smiselno odločiti, če
graf ni prevelik (največ 200 do 300 točk). Sicer je pred tem smiselno
opraviti še kakšno analizo in na osnovi te analize
izločiti in narisati samo izbrani podgraf.
Graf lahko narišemo z uporabo energijskega risanja
(Draw/ Energy/ Kamada-Kawai ali
Draw/ Energy/ 2D Fruchterman-Reingold), ali pa z uporabo
risanja prirejenega za risanje rodovnikov.
To vrsto risanja poženemo z uporabo ukaza makro:
Macro/ Play
in nato poiščemo kje se nahaja datoteka Layers.mcr
(ponavadi na podpodročju Genea).
Dobljeno sliko lahko še izboljšamo z uporabo ukaza
Draw/ Draw-Partition/ Layers/ Optimize layers in xy,
ki nam skuša dobljeno razvrstitev po nivojih narisati s
čim krajšimi povezavami (izbiramo lahko še med različnimi
natančnostmi v podizbiri Draw/ Draw-Partition/ Layers/ Resolution.
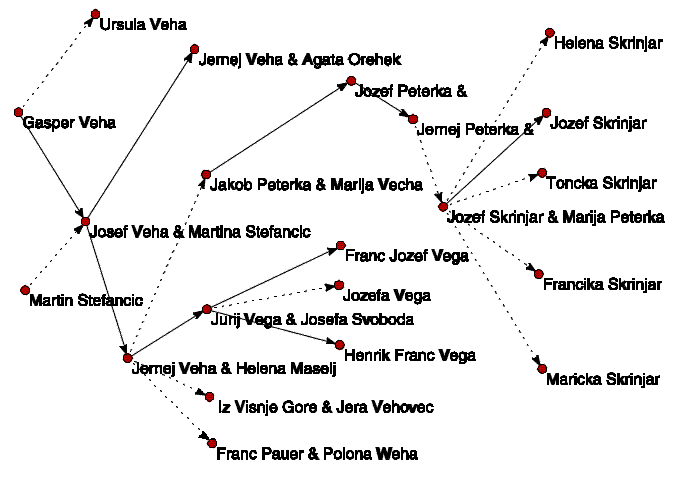
Na sliki 3 je na ta način narisan rodovnik
Jurija Vege (v obliki p-graph z obrnjenimi puščicami).
Slika 3. Rodovnik Jurija Vege.
EPS
|
Iskanje najkrajše sorodstvene zveze med dvema osebama
Tudi za iskanje in risanje najkrajše sorodstvene zveze med dvema osebama
je pripravljena datoteka z ukazom makro -- path.mcr. Poženemo jo na
isti način kot prejšnje, le da moramo še določiti obe osebi (odtipkamo
lahko številko ali vsaj začetek imena).
Za primer smo uporabili podatke z datoteke Drame.ged (rodovnik
Leona Drameta), v kateri se nahajajo podatki o 29606 osebah.
Datoteka je sestavljena iz 703 ločenih komponent, od katerih je ena
zelo velika (z 19854 osebami), ostale pa so manjše. Število komponent
ugotovimo z ukazom Net/ Components/ Weak ter dobljeni rezultat
pogledamo z Info/ Partition. Če si zapomnimo številko
neke komponente, jo lahko kasneje izločimo iz grafa z ukazom
Operations/ Extract from Network/ Partition, kjer dvakrat
odtipkamo številko željene komponente.
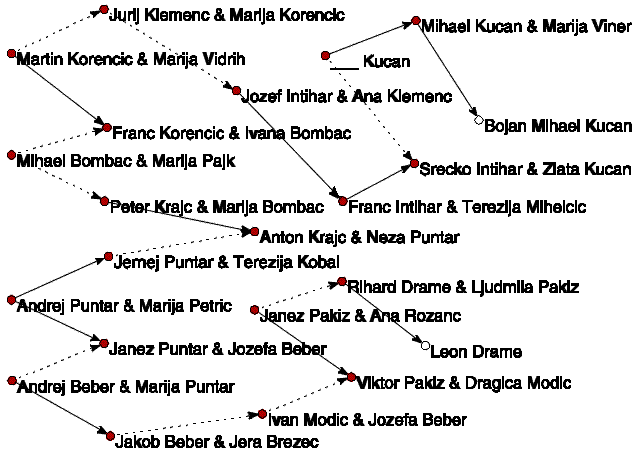
Slika 4 prikazuje najkrajšo pot med Leonom Drametom
in Bojanom Mihaelom Kučanom, če uporabimo navaden rodovnik;
slika 5 pa najkrajšo pot, če uporabimo rodovnik v obliki p-graph
(v tem primeru imamo v grafu namesto 29606 samo 22193 točk). Opazimo
lahko, da se poti malo razlikujeta, ker smo v primeru navadne oblike šteli
za korak tudi poroko (neusmerjeno povezavo).
Slika 4. Najkrajša pot (navadna oblika).
EPS
|
Slika 5. Najkrajša pot (p-graph).
EPS
|
Iskanje okolice izbrane osebe
Če imamo opravka z velikim grafom, se je smiselno omejiti na neko okolico
izbrane osebe. Podgraf, ki ga sestavljajo osebe, ki so od izbrane osebe
oddaljene največ za tri generacije dobimo tako, da poženemo makro
3bef3lat.mcr in dvakrat odtipkamo željeno osebo.
Število neposrednih potomcev izbrane osebe
Z ukazom Net/ Partition/ Degree/ Output ugotovimo, koliko povezav
vodi od posameznih točk v grafu. Informacijo si lahko v skrčeni obliki
pogledamo z ukazom
Info/ Partition ter odtipkamo neko številko, npr. 10 -- želimo
videti prvih 10 oseb z največjim številom otrok. Številko ali ime osebe,
ki ima največ otrok si zapomnimo, in poženemo
Net/ k-Neighbours/ Output
(izračunamo oddaljenosti od te osebe), ter z ukazom
Operations/ Extract from Network/ Partition
(vnesemo 0 in 1) izločimo le osebo samo (ki je na oddaljenosti 0)
in njene potomce (na oddaljenosti 1).
Vzemimo spet podatke
Drame.ged. Če preberemo datoteko v navadi obliki, dobimo kot rezultat
osebo z največ otroki (skupno), kar je prikazano na
sliki 6; če pa datoteko preberemo v obliki p-graph, dobimo
zakonski par z največ otroki (slika 7).
Slika 6. Posameznik z največ otroki (navadna oblika).
EPS

|
Slika 7. Zakonski par z največ otroki (p-graph).
EPS
|
Iskanje zanimivih vzorcev
S programom Pajek lahko odkrijemo tudi zanimive
vzorce v rodovnikih (poroke med sorodniki).
Rodovnik najprej preberemo v obliki p-graph.
Nad njim izračunamo dvopovezane komponente z ukazom
Net/ Components/ Bi-Components, pogledamo informacijo o komponentah
Info/ Hierarchy ter odtipkamo neko številko, npr. 10 -- želimo
videti 10 največjih dvopovezanih komponent. Če se v rezultatu pojavijo
samo komponente velikosti 2, je vse v redu. Večje komponente
pa so bolj zanimive.
Tabela 1 prikazuje porazdelitev velikosti komponent
v primeru podatkov Drame.ged.
Table 1. Porazdelitev števila točk v dvopovezanih komponentah.
število točk
v komponenti | število
komponent |
| 2 | 19474 |
| 3 | 1 |
| 4 | 11 |
| 6 | 3 |
| 7 | 1 |
| 11 | 1 |
| 12 | 1 |
| 144 | 1 |
| 1602 | 1 |
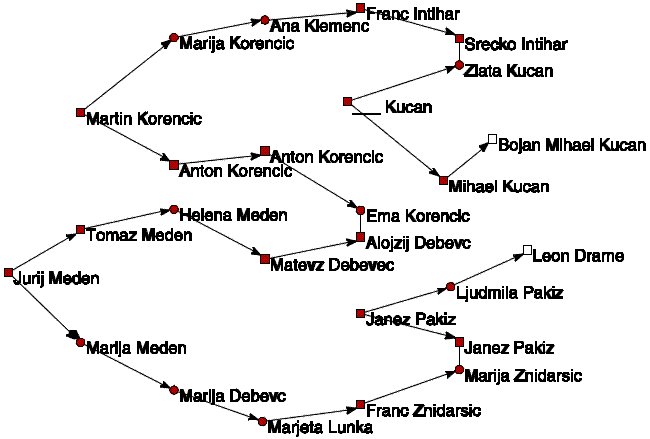
Dvopovezane komponente sestavljene iz lihega števila točk ponavadi
pomenijo generacijske preskoke, medtem ko komponente sestavljene
iz sodega števila točk večkrat pomenijo poroke med sorodniki.
Posebno 'nevarne' so seveda tiste z majhnim številom točk --
poročajo se bližnji sorodniki.
Številko izbrane komponente si zapomnimo in jo
izločimo z ukazom Hierarchy/ Extract Cluster
(dobimo množico
oseb v tej komponenti), nato pa to množico izločimo iz grafa z ukazom
Operations/ Extract from Network/ Cluster, ter jo po želji narišemo
kot smo že opisali.
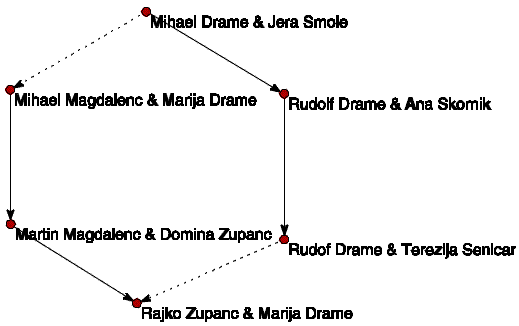
Slika 8 prikazuje enega od zanimivih vzorcev (šestkotnik)
v datoteki Drame.ged.
Slika 8. Poroka med sorodniki.
EPS
|
V tabeli 1 sicer lahko preberemo, da so v datoteki tri
dvopovezane komponente velikosti šest, vendar to še ne pomeni, da
v grafu ni mogoče najti še več šestkotnikov. Dvopovezane komponente
namreč ne odkrijejo tistih vzorcev, ki so 'vpeti' v večje komponente.
Predpostavimo, da želimo v grafu najti vse vzorce, ki se po obliki
ujemajo s tistim na sliki 8.
Za iskanje vzorcev uporabimo podprogram Fragment.
Potem, ko smo šestkotnik na sliki 8
izločili iz rodovnika ga izberemo v spisku omrežij in proglasimo za
vzorec z ukazom Nets/ First Network. Celoten rodovnik pa
z ukazom Nets/ Second Network označimo za omrežje v katerem bomo
iskali izbrani vzorec. Nato poženemo ukaz Nets/ Fragment (1 in 2)/ Find,
ki nam poišče vse šestkotnike v rodovniku. Vsa ujemanja z vzorcem
se shranijo v razbitju (Partition). V primeru manjšega rodovnika
lahko rezultat pogledamo z ukazom Draw/ Draw-Partition v primeru
večjega pa ujemanja izločimo z ukazom
Operations/ Extract from Network/ Partition, kjer dvakrat
odtipkamo številko 1.
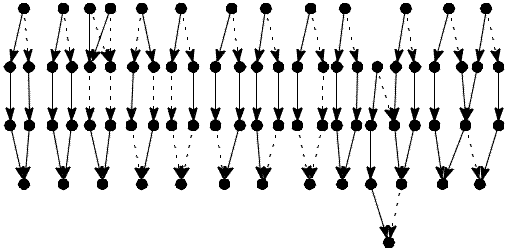
Slika 9 prikazuje vse šestkotnike v datoteki
Drame.ged (ne glede na spol, ki je v primeru rodovnikov v obliki
p-graph predstavljen z vrsto povezave: ženske-crtkano, moški-polna črta).
Vseh šestkotnikov je torej 14.
Slika 9. Vsi šestkotniki.
EPS
|
Pri iskanju šestkotnikov lahko postavimo še dodatne zahteve,
kdaj pride do ujemanja z vzorcem. Te zahteve opišemo z ukazom
Nets/ Fragment (1 in 2)/ Options:
- Induced -- Če je ta zahteva izbrana, pomeni da
mora skupina točk v rodovniku za ujemanje z vzorcem generirati
izbrani vzorec.
Razlaga: Če izločimo skupino točk iz rodovnika skupaj
z vsemi povezavami, ki imajo krajišča v teh točkah, moramo dobiti ravno
vse tiste povezave, ki so tudi v vzorcu in nobene dodatne.
(v omenjenem primeru šestkotnika ne sme obstajati nobena dodatna povezava
razen šestih stranic le tega).
Če pa ta zahteva ni izbrana in je v izločeni podskupini še kakšna dodatna
povezava, le ta ujemanja z vzorcem ne prepreči.
- Labeled -- Pride v poštev pri iskanju vzorcev v molekulah
(imena v vzorcu in omrežju se morajo ujemati --
pri molekulah so oznake točk imena atomov).
Pri iskanju vzorcev v rodovnikih ta zahteva ne sme
biti izbrana.
- Check values of lines -- Ko smo v zadnjem primeru iskali vse
šestkotnike, se nismo ozirali na spol oz. vrednost povezav
(moški imajo vrednost 1, ženske pa 2).
Če želimo, da do ujemanja z vzorcem pride le, če se
ustrezne povezave ujemajo tudi po vrednosti, moramo
kot lastnost vzorca zahtevati tudi Check values of lines.
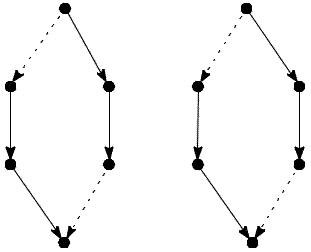
Slika 10 prikazuje oba šestkotnika,
ki se ujemata tudi po spolu z vzorcem na sliki 8.
- Check only Cluster -- Če pričakujemo, da bo v rodovniku veliko
ujemanj z danim vzorcem, oziroma nas vsa ujemanja niti ne zanimajo,
se je smiselno omejiti samo na iskanje vzorcev v izbrani
podmnožici oseb. To podmnožico podamo kot Cluster --
spisek številk oseb iz rodovnika. Te številke lahko
zapišemo v datoteko s podaljškom CLS in podmnožico
preberemo z ukazom File/ Cluster/ Read. Če
je rodovnik manjši in imamo že narisano sliko,
pa poženemo ukaz Draw-SelectAll, s srednjo
tipko na miški izberemo točke v dani podmnožici
in točke izločimo z ukazom Partition/ Make Cluster
kjer dvakrat odtipkamo številko 1.
Poleg tega je treba v vzorcu označiti še, katera oseba je tista,
ki mora biti v izbrani podmnožici.
To naredimo tako, da nad vzorcem poženemo datoteko z ukazom makro
Selected.mcr in odtipkamo številko točke, ki naj bo izbrana
(makro točke preštevilči, tako da dobi izbrana točka
številko 1). Nato dobljen vzorec proglasimo za veljavni vzorec
z ukazom Nets/ First Network.
Slika 10. Vsi šestkotniki, ki se ujemajo po spolu.
EPS
|
Pajek;
Vlado/Networks